
John Tsotsos (York University), “Attentional Mechanisms Bridge Seeing to Looking”
20 June @ 2:15 pm - 3:45 pm
David Marr wrote ‘What does it mean, to see? The plain man’s answer (and Aristotle’s, too) would be, to know what is where by looking‘. Modern vision science has moved beyond Aristotle’s view as well as Marr’s, although it certainly would not have advanced without the influence of both. Seeing and Looking are different and although related in a plain manner, at a deeper mechanistic level it is not plain at all: they are spatially, temporally and causally connected.
We examine Looking and Seeing and the roles they play in a rational visual agent that functions purposefully in a real three-dimensional world, as a plain person, Marr, or Aristotle would behave during their lifetimes. The vast bulk of theoretical, experimental and empirical research has focussed on how an agent views and perceives an image, singly or in video sequence. We add to the small but growing literature that addresses how an agent chooses how to view a three-dimensional world in the context of a real world task. Looking is the result of a change of gaze while Seeing is what occurs during the analysis of what is being looked at and causes a particular next Looking act. Gaze change ranges over a full 6 degrees-of-freedom for head pose and 3 degrees-of-freedom for each of two eyes within that head.
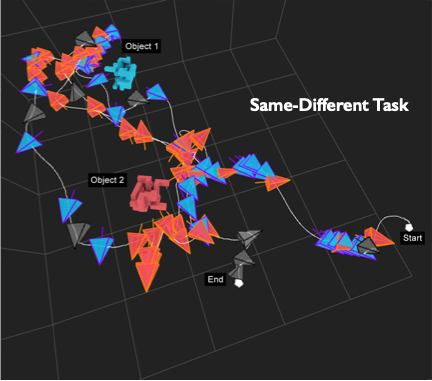
Although our past research has shown that sensor viewpoint planning has provably exponential complexity properties, we propose that an array of attentional mechanisms, as found in our Selective Tuning model, tame the complexity of such behaviour and provides the bridge between Seeing and Looking. Through extensive human experiment (one of these is the pictured Same-Different Task) and foraging through the history of computational vision, we are gradually constructing a picture of a complex blend of orchestrated attentional, visual, reasoning, planning and motor behaviours required for real-world 3D visual tasks.
Photo provided by the speaker.
Marchstr. 23 – MAR 5-2
10587 Berlin
Email: info@scioi.de
Tel: +49 30 314 77344




![]()